

We maken daarbij graag gebruik van het data lake concept: een centrale verzamelplaats voor data uit verschillende bronnen en van verschillende formaten, zodat we vanaf één plek kunnen analyseren en combineren. Natuurlijk kunnen we dan zelf bijvoorbeeld een dashboard ontwikkelen om de opgedane inzichten te delen met business gebruikers, maar nog mooier is het als deze mensen zelf met de data aan de slag kunnen. In deze blog laat ik drie manieren zien hoe we dit voor elkaar kunnen krijgen, gebaseerd op de Microsoft Azure stack.
Data lake zones
Even bij het begin beginnen: dat data lake. In Azure wordt een ‘Data Lake Storage’ aangeboden, wat in feite Hadoop (specifiek HDFS) as a service is: hiërarchische file storage die het best te benaderen is met Spark. De hoofdmappen op het data lake noemen we ook wel ‘zones’. In de ‘raw’ zone wordt data uit de bronsystemen onbewerkt neergezet. Het schoonmaken, koppelen en oppoetsen van deze data leidt tot de bestanden die we in de ‘curated’ zone neerzetten: gestructureerde datasets (in bijvoorbeeld CSV-formaat) met duidelijke naamgeving van de kolommen en velden. Deze zones worden ook wel aangeduid met bronze/silver/gold, zoals in het plaatje hieronder.
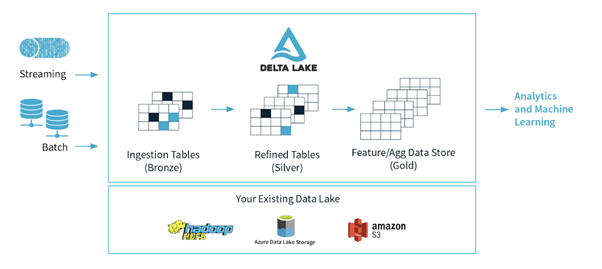
Architectuur van Delta Lake (https://delta.io) waar de verschillende data lake zones neer worden gezet.
In een toekomstig blog gaan we misschien nog verder in op hoe je zo’n data processing pipeline opzet, maar voor nu gaan we er vanuit dat er nette curated data op het data lake staat. Nu komt er een vraag van een gebruiker die wel handig is met Power BI en graag met die data aan de slag wil. Hoe richten we dit goed in? Hiervoor zijn een aantal verschillende mogelijkheden.
Optie 1: direct op het data lake
Het meest eenvoudige is om de gebruiker direct toegang te geven tot de files op het data lake. De gebruiker kan dan zelf via Power BI iedere file apart ophalen en moet hierna zelf de datasets aan elkaar koppelen om een datamodel te maken. Hoewel deze oplossing het meest eenvoudig is om te realiseren, is ze ook het minst gebruiksvriendelijk, en kan een gebruiker zo wellicht de data verkeerd koppelen en daarmee onjuiste conclusies trekken. Maar het is een logische eerste stap om gebruikers zelf aan het analyseren van data te zetten, zeker als de modellen nog niet heel complex (i.e. meerdere datasets en relaties) zijn.
Optie 2: dataset in de Power BI Service
Een volgende stap is om die modellen zelf op te leveren. Door het model te maken in Power BI (zonder een dashboard aan de voorkant) en deze te uploaden naar de Power BI Service (de cloud) stel je gebruikers in staat om vanaf hun desktop te verbinden met zo’n model. Zij kunnen het model vervolgens niet wijzigen, maar er wel allerlei rapportages op bouwen. Een dergelijk model wordt ook wel een golden dataset genoemd. Met de gratis Power BI workspaces in de Service kom je een heel eind, maar er zitten limieten aan de hoeveelheid data in een model en aan de performance, wat je gaat merken als meerdere mensen tegelijk van het model gebruik willen maken.
Daarnaast kun je de Power BI Desktop bestanden niet handig in versiebeheer zetten (het is geen platte tekst), wat betekent dat er nog relatief veel handmatige stappen zijn in het aanmaken en onderhouden van deze datamodellen. Technisch is het dus niet ideaal, maar de user experience is al een heel stuk soepeler dan in het eerste scenario. Deze oplossing vormt een zeer aantrekkelijke middenweg tussen functionaliteit en complexiteit en zal dan ook in veel gevallen te gebruiken zijn.
Optie 3: Azure Analysis Services
Wil je het echt groots aan pakken, dan kun je terecht bij Azure Analysis Services (AAS, de cloud versie van SQL Server Analysis Services). Hierin kun je op eenzelfde wijze als in Power BI datasets inladen en koppelen, maar worden de modellen nu los van de data opgeslagen als JSON (dus versiebeheer is weer mogelijk!) en werkt AAS met een in-memory cache om de data supersnel beschikbaar te stellen aan de gebruikers.
Dit betekent dat de user experience optimaal is, ook als het aantal simultane gebruikers toeneemt (de AAS-capaciteit is eenvoudig op te schalen via de Azure portal). Hier staat tegenover dat dit, van de drie oplossingsrichtingen in deze blog, verreweg de duurste is (de kleinste AAS server kost al ruim 250 euro per maand, al kun je relatief eenvoudig besparen door deze bijvoorbeeld ’s nachts uit te zetten) en daarnaast ook het meest complex om in te richten en te beheren.
Er is bijvoorbeeld geen out-of-the-box ondersteuning voor deployment van modellen via Azure DevOps of het refreshen van een model als stap in een Azure Data Factory pipeline. Wel is er een Tabular Model Scripting Language (TMSL) die erg krachtig is, maar slechts mondjesmaat gedocumenteerd. Misschien wel de grootste tekortkoming in mijn ogen is dat hoewel Azure Data Lake Storage wordt ondersteund als bron, de credentials hiervoor niet bewaard kunnen worden, en dus moet je in dit scenario iedere ochtend met de hand de modellen verversen. Of toch een SQL-database ertussen gaan zetten, wat weer nog meer kosten en onderhoud met zich meeneemt. Deze oplossingsrichting wordt interessant voor bedrijven met meerdere dedicated BI-teams en rapportages die door vele gebruikers tegelijk worden gelezen.
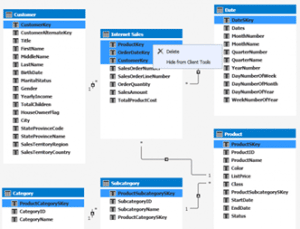
Voorbeeld datamodel in Analysis Services, van www.sqlshack.com
Drie mogelijke oplossingen, met ieder hun eigen voor- en nadelen. Natuurlijk zijn er nog tal van andere manieren om ‘Data as a service’ mogelijk te maken, maar een silver bullet is er in ieder geval niet, je zult altijd moeten kijken naar de context van jouw organisatie. Met deze blog hoop ik je wat aanknopingspunten te hebben gegeven; heb je meer hulp nodig, neem dan gerust contact op en we kijken wat we voor je kunnen betekenen. Heb je hier al ervaring mee en weet je nog een betere oplossing, dan hoor ik dat natuurlijk ook graag.



